Improving Deep Learning Based Anomaly Detection on Multivariate Time Series Through Separated Anomaly Scoring
Mid Sweden University
Holmgatan 10, 85170 Sundsvall, Sweden
Institute of Comptuer Technology
Vienna, Austria
Faculty of Science
University of Ontario Institute of Technology
2000 Simcoe St. N., Oshawa ON L1G 0C5, Canada
Abstract
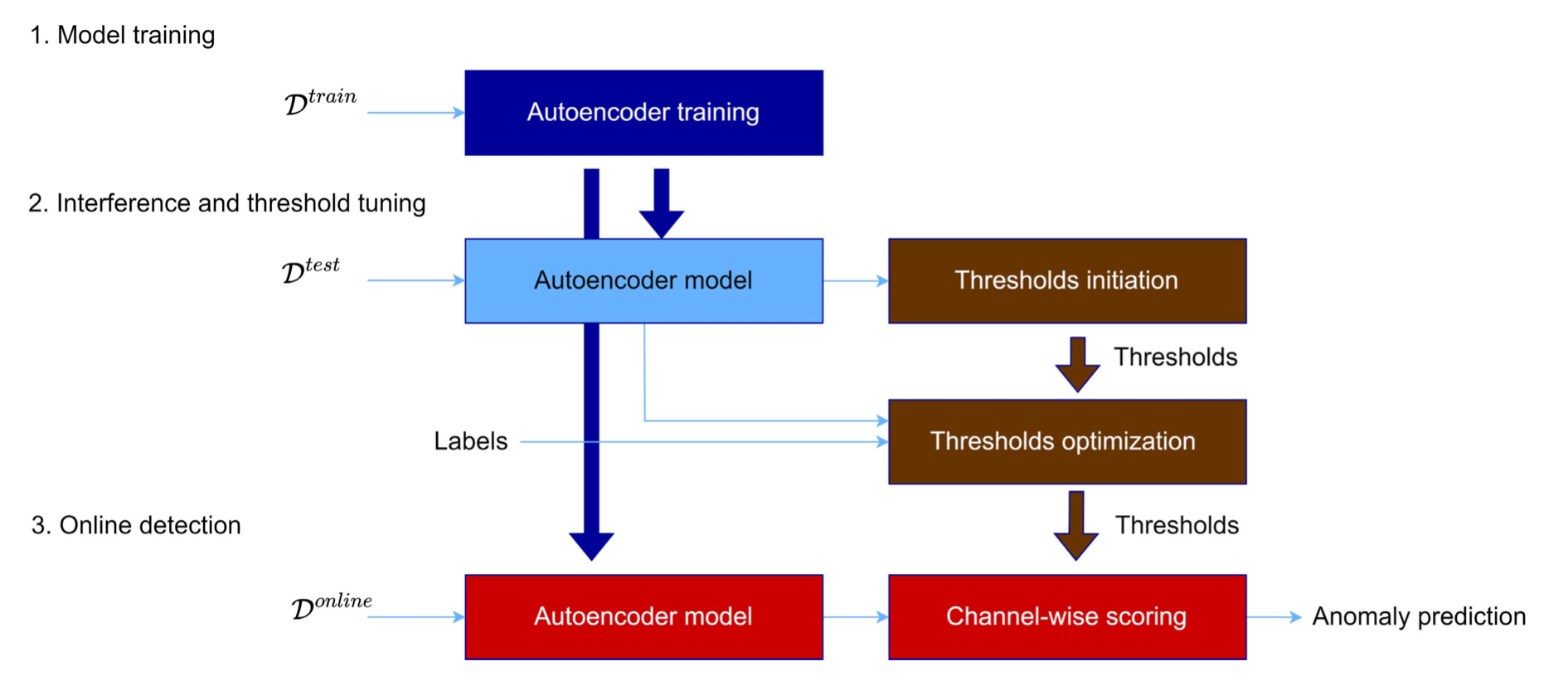
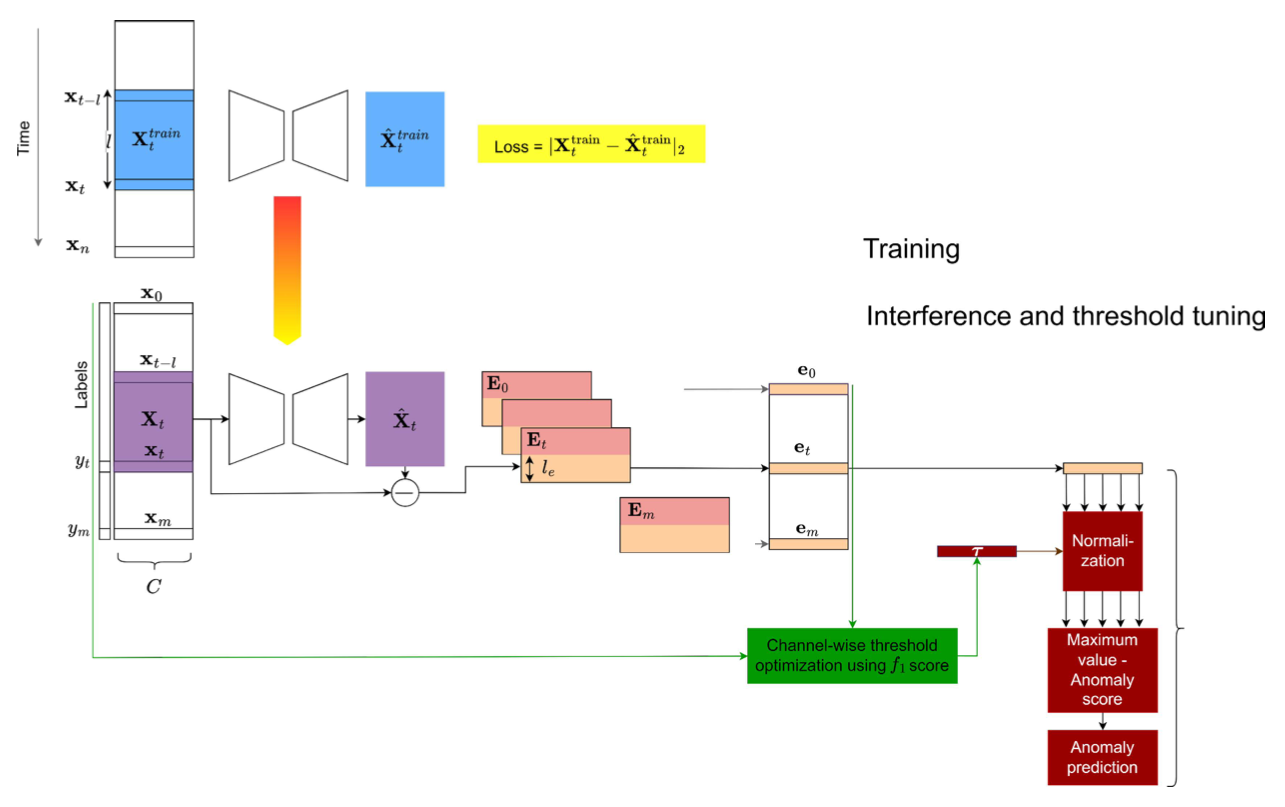
The importance of anomaly detection in multivariate time series has led to the development of several prominent deep learning solutions. As a part of the anomaly detection process, the scoring method has shown to be of significant importance when separating non-anomalous points from anomalous ones. At this time, most of the solutions utilize an aggregated score which means that relevant information created by the anomaly detection model might be lost. Therefore, this study has set out to examine to what extent anomaly detection in multivariate time series based on deep learning can be improved if all the residuals from each individual channel is considered in the anomaly score. To achieve this, an aggregated and separated scoring method has been applied with a simple denoising convolutional autoencoder. In addition, the performance has been compared with other state-of-the-art methods. The result showed that the separated approach has the potential to generate a significantly higher performance than the aggregated one. At the same time, there were some indications suggesting that an aggregated scoring is better at generalizing when no labels are available to select the anomaly thresholds. Therefore, the result should serve as an encouragement to use a separated scoring approach together with a small sample of labeled anomalies to optimize the thresholds. Lastly, due to the impact of the anomaly score, the result suggests that future research within this field should consider applying the same anomaly scoring method when comparing the performance of deep learning algorithms.
Synopsis
This study aims to address the following question:
To what extent can the performance of multivariate anomaly detection on time series data based on deep learning be improved by constructing an anomaly score considering the residuals of each individual channel separately?
This study explores this question by setting up a convolutional autoencoder based anomaly detection method that is evaluated on standard benchmarks using both separated scoring and aggregated scoring techniques. We find that separated approach significantly outperforms the aggregated approach on the three datasets that we have used.
Publication
For technical details please look at the following publications